IT operations manager
Service delivery lead
Incident commander
Operations director
Customer success manager
VP of engineering

This process is used when an incident exceeds the resolution capacity or authority of the initial response team and requires engagement from additional resources, specialists, or management. It is triggered when resolution timelines exceed defined SLA thresholds, when the incident’s severity is reassessed upward based on expanding impact, when customer or business exposure reaches a level requiring management visibility, or when cross-functional coordination is needed to contain the issue. This process is common in technology operations, IT service management, financial services, healthcare, and any organization where operational incidents carry significant business or customer impact.
The incident escalation process typically involves frontline responders who identify the need for escalation, technical specialists or subject matter experts who are engaged for advanced troubleshooting, incident managers or commanders who coordinate the escalation response, operations or service delivery managers who assess business impact and prioritize resources, customer-facing teams who manage communication with affected stakeholders, and senior leadership who authorize high-impact response actions or resource reallocation.
Faster incident containment by engaging the right expertise and authority level as soon as initial response proves insufficient. Reduced business impact through structured severity reassessment that triggers additional resources before the situation deteriorates further. Coordinated cross-team response where all responders share visibility into incident status, actions taken, and next steps. Clear communication to affected stakeholders with timely updates as the incident progresses through escalation tiers. Documented resolution path that captures every escalation step, responder action, and decision for post-incident review and process improvement.
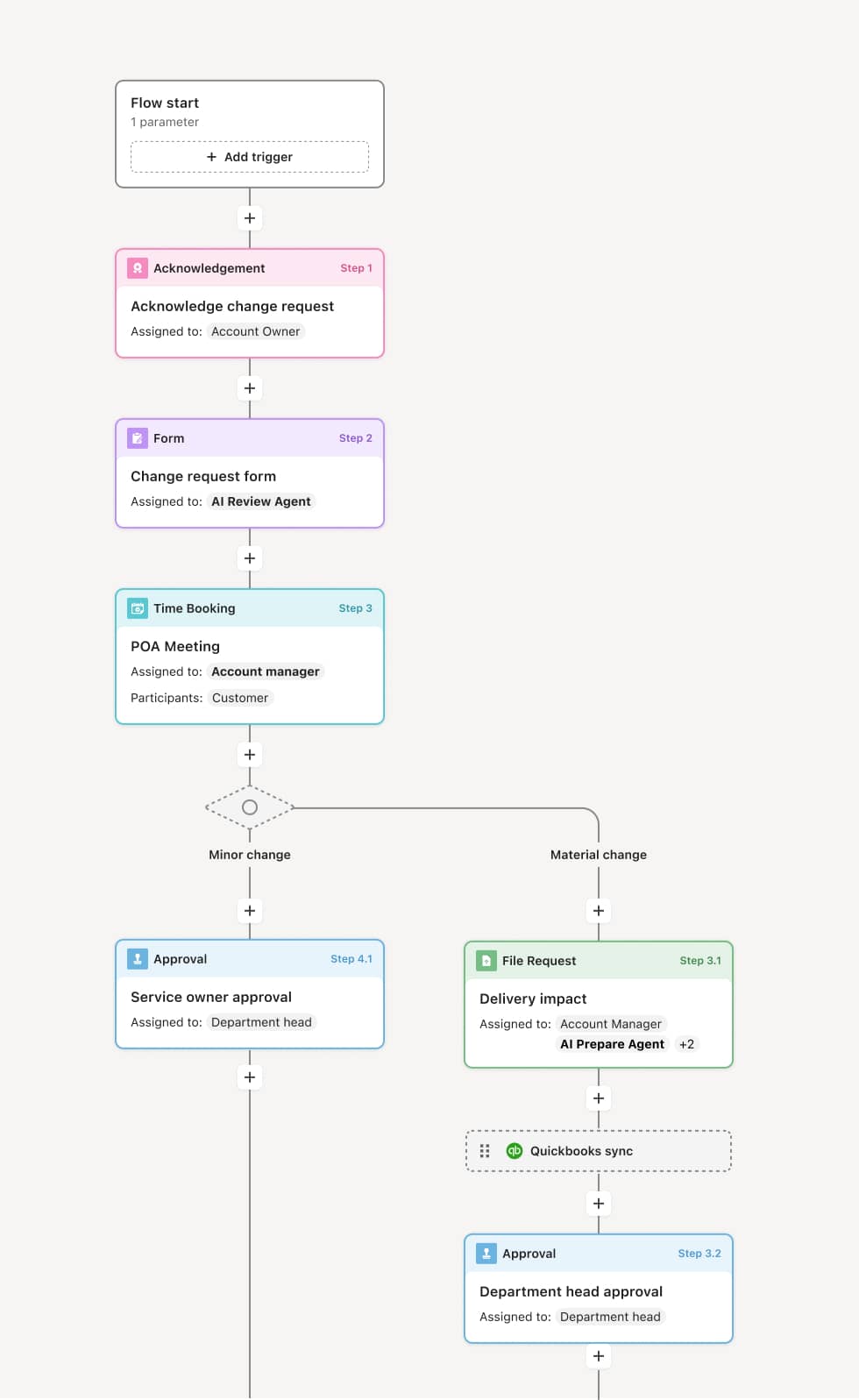
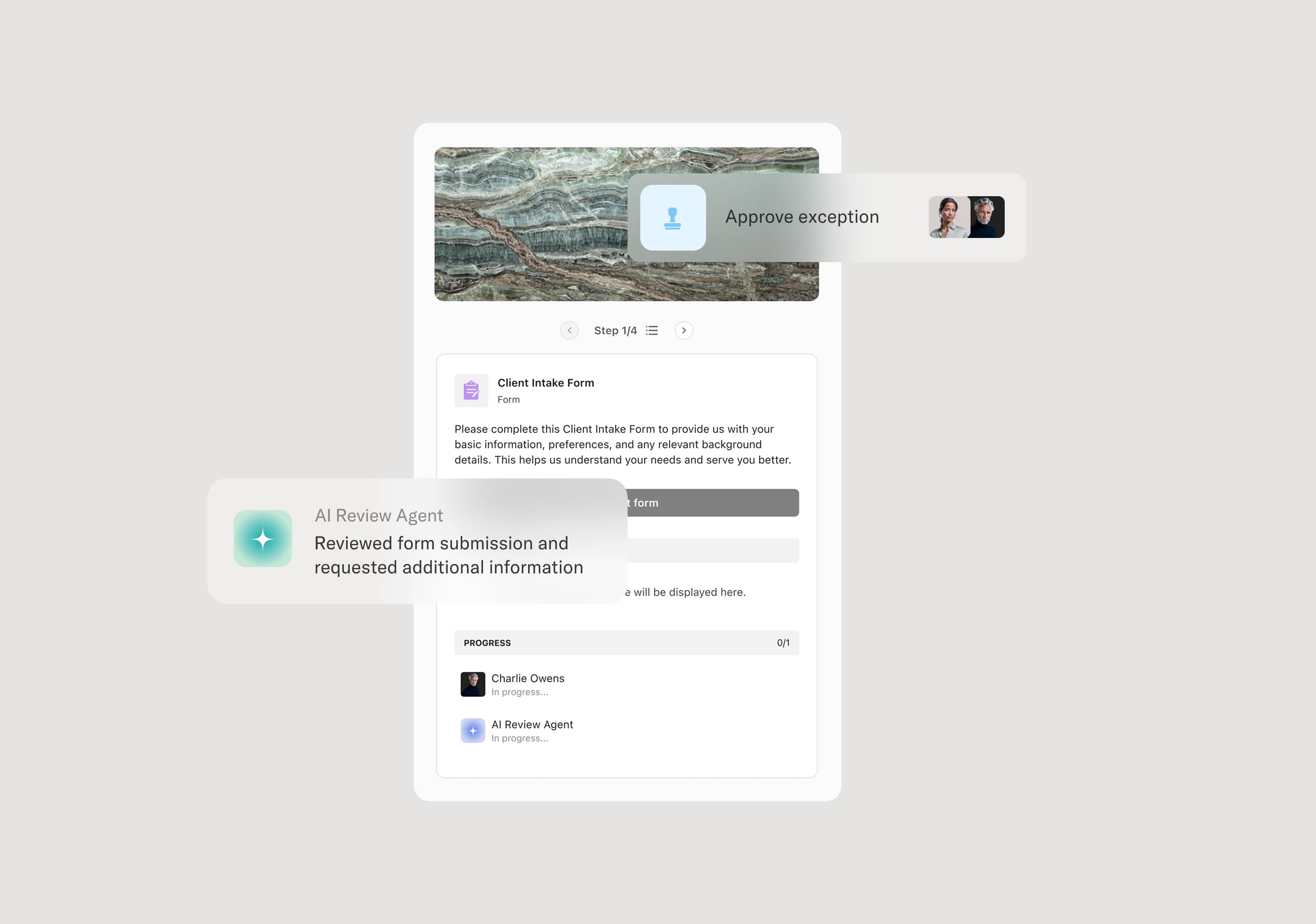
Your version of this process may vary based on roles, systems, data, and approval paths. Moxo’s flow builder can be configured with AI agents, conditional branching, dynamic data references, and sophisticated logic to match how your organization runs this workflow. The steps below illustrate one example.
Escalation trigger identification
The process begins when an existing incident meets escalation criteria, which may include an approaching or breached SLA, an expanding blast radius affecting additional systems or customers, a failed initial remediation attempt, or a severity reassessment by the frontline team. An AI Agent may assist by monitoring incident timelines and automatically flagging cases that meet escalation thresholds.
Severity reassessment and routing
Once escalation is triggered, the incident’s severity is formally reassessed based on current impact, scope, and urgency. This reassessment determines the escalation tier and the teams or individuals who need to be engaged. The workflow routes the incident to the appropriate responders, whether that is a senior engineer, an incident commander, a service delivery manager, or a cross-functional response team. The AI Agent may compile a current-state summary including the timeline, actions taken, and outstanding gaps.
Specialist engagement and response coordination
The escalated responders review the incident context and take ownership of the next phase of response. This may involve advanced technical troubleshooting, cross-system investigation, vendor engagement, or resource reallocation. The workflow coordinates parallel work streams when multiple teams are involved, ensuring actions are visible and dependencies are tracked.
Stakeholder communication
As the incident escalates, communication to affected stakeholders, whether internal business units, customers, or partners, is managed within the workflow. Updates are prepared and distributed at defined intervals or when significant status changes occur. The AI Agent may draft status updates based on the latest incident data for review before distribution.
Containment, resolution, and de-escalation
Once the incident is contained and the root cause is addressed or mitigated, the incident moves toward resolution. The resolution is confirmed, affected systems or processes are verified as operational, and the incident is de-escalated. Stakeholders are notified of the resolution and any follow-up actions.
Post-incident review and closure
The incident record is finalized with a complete timeline, all escalation decisions, responder actions, and resolution details. This record supports post-incident reviews, root cause analysis, and identification of process improvements. If the incident revealed systemic vulnerabilities or response gaps, the workflow may trigger a follow-up improvement initiative.
This process commonly relies on inputs such as incident tickets, monitoring alerts, SLA status data, system logs, customer impact reports, and prior resolution attempts. It may be triggered by an SLA timer, a manual escalation from the frontline team, or an automated severity reassessment. Systems commonly connected include ITSM platforms like ServiceNow for incident tracking, monitoring and alerting systems for real-time status, and CRM tools like Salesforce for customer impact context.
Key decision points include whether the incident meets escalation criteria, what severity level is appropriate based on current impact, which teams or specialists need to be engaged, whether containment actions require management authorization, and when the incident can be de-escalated and closed. If the incident continues to expand despite escalation, further tiers of response may be triggered based on configured thresholds.
Escalation triggered too late, allowing the incident to expand and increase business impact before additional resources are engaged. Severity reassessment not performed, causing the incident to be handled at an inappropriate response level. Responder handoffs losing critical context, forcing new participants to re-investigate before they can contribute. Stakeholder communication delayed or inconsistent, eroding trust and creating confusion about incident status. Post-incident review not conducted, missing opportunities to improve response processes and prevent recurrence.
AI Agents monitor incident timelines and automatically flag cases that meet escalation thresholds, reducing the risk of delayed response.
Routes escalated incidents to the correct responders and authority levels based on severity, impact scope, and required expertise.
Coordinates parallel response streams across multiple teams within a single workflow, ensuring all responders share visibility and context.
Prepares stakeholder communication by compiling incident status data and drafting updates for human review before distribution.
Maintains a complete incident escalation record from trigger through resolution, supporting post-incident review, root cause analysis, and continuous improvement.