IT service manager
Operations director
Incident response lead
Service delivery manager
Chief technology officer
Process improvement lead

This process is used when an organization needs a repeatable, scalable framework for managing incident escalations across severity levels and response tiers. It applies when the organization manages a volume of incidents where ad-hoc escalation creates inconsistency, when SLA commitments require predictable response timelines at each severity level, when incidents frequently span multiple teams or external vendors, and when post-incident reviews consistently identify escalation gaps as a root cause of extended impact. This process is common in IT operations, managed services, financial technology, healthcare systems, and any organization where incident response maturity directly affects service quality and business continuity.
The incident escalation process typically involves frontline support or operations teams who handle initial response and first-tier escalation, technical specialists and subject matter experts who are engaged at higher escalation tiers, incident managers who coordinate multi-team response efforts, service delivery or operations managers who oversee SLA performance and resource allocation, and senior leadership who authorize high-impact response actions such as emergency changes, vendor escalations, or customer communications.
Predictable escalation response with defined timelines, authority levels, and actions at each tier. Reduced mean time to resolution because escalation paths are pre-defined and context is prepared before responders are engaged. Consistent SLA performance through automated monitoring of escalation timelines and proactive trigger management. Improved cross-team coordination with shared incident context and clear ownership at every escalation stage. Actionable post-incident data that identifies where the escalation process worked, where it broke down, and what should be improved.
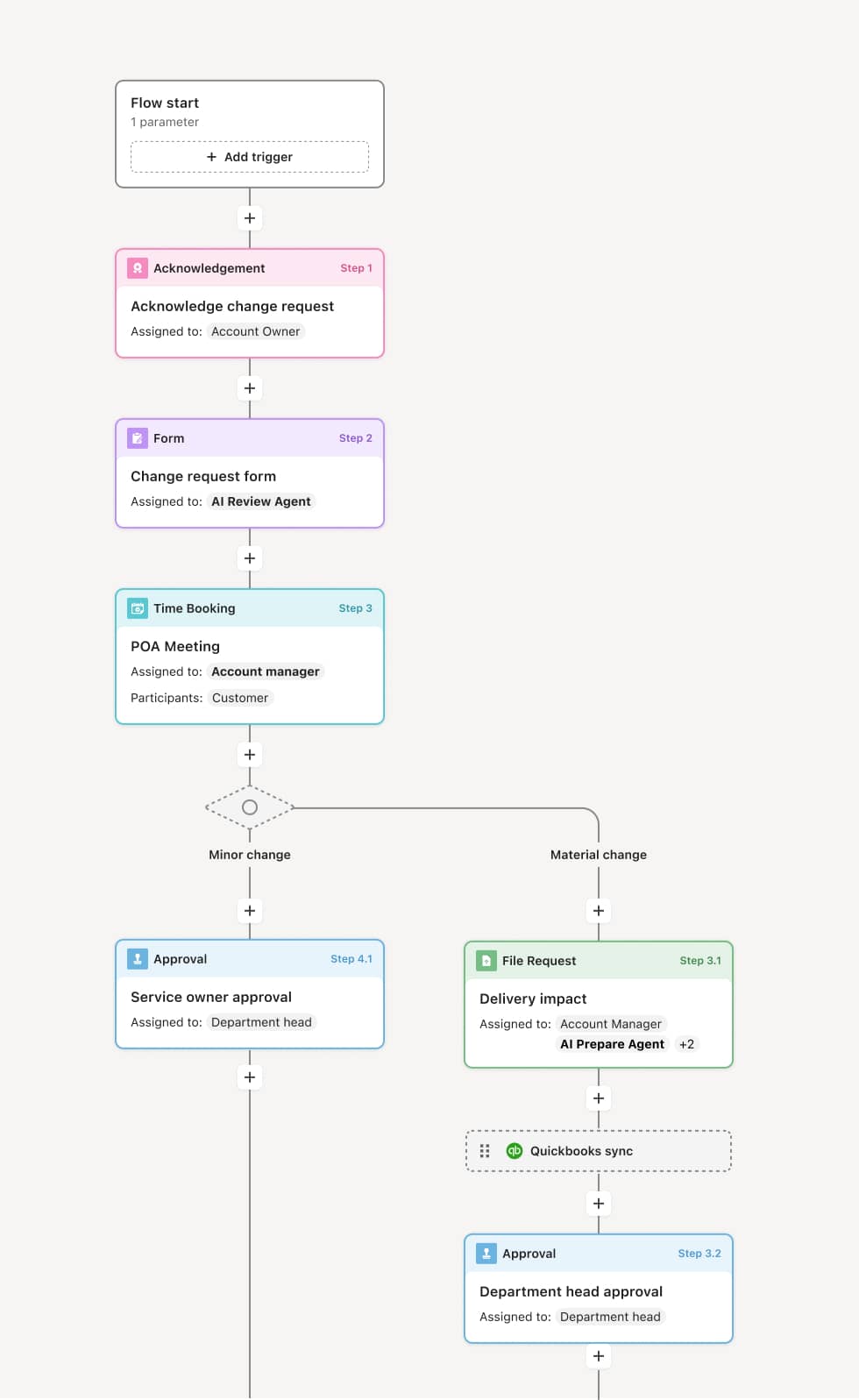
Your version of this process may vary based on roles, systems, data, and approval paths. Moxo’s flow builder can be configured with AI agents, conditional branching, dynamic data references, and sophisticated logic to match how your organization runs this workflow. The steps below illustrate one example.
Incident intake and initial classification
The process begins when an incident is reported or detected, and the frontline team performs initial classification including severity, impact scope, affected systems, and urgency. The classification determines the initial response path and the applicable SLA timeline. An AI Agent may assist by enriching the incident record with related alerts, known issues, and affected customer data.
Tier-1 response and monitoring
The frontline team executes the initial response according to standard procedures. During this phase, the workflow monitors the incident against SLA timelines. If the incident is resolved within the Tier-1 window, it is closed with a documented resolution. If the SLA threshold is approaching or the frontline team determines they cannot resolve the issue, the incident moves to escalation.
Tier-2 escalation and specialist engagement
The incident is escalated to a senior technical resource or subject matter expert with the relevant domain expertise. The AI Agent compiles a handoff summary including all actions taken, diagnostic data collected, and the current hypothesis. The Tier-2 responder reviews the context and takes ownership of the next phase of investigation and remediation.
Tier-3 escalation for critical or unresolved incidents
If the incident remains unresolved or its severity increases, it escalates to Tier-3, which typically involves the incident manager, cross-functional teams, vendor support, or senior engineering leadership. At this tier, the response may include parallel troubleshooting streams, emergency change authorizations, or external vendor engagement. The workflow coordinates all participants and tracks progress against updated SLA expectations.
Management visibility and stakeholder communication
At each escalation tier, management visibility increases. The workflow ensures that the appropriate level of management is informed and that stakeholder communications are issued according to the communication plan for the incident’s severity. The AI Agent may prepare status updates for management review.
Resolution, de-escalation, and closure
Once the incident is resolved, the resolution is confirmed, affected services are verified, and the incident is de-escalated through the tiers. Stakeholders receive final resolution notifications. The complete escalation record, including all tier transitions, responder actions, timeline data, and resolution details, is stored for post-incident review and process improvement.
This process commonly relies on inputs such as incident reports, monitoring alerts, SLA definitions, system diagnostic data, known issue databases, and customer impact reports. It may be triggered by a monitoring alert, a user-reported issue, or an automated detection system. Systems commonly connected include ITSM platforms like ServiceNow for incident management, monitoring tools for system health data, and CRM platforms like Salesforce for customer context and communication tracking.
Key decision points include the initial severity classification that determines the response path, whether the incident can be resolved within the current tier or requires escalation, what expertise or authority is needed at the next tier, whether emergency changes or vendor escalations are warranted, and when the incident can be declared resolved and de-escalated. Each tier transition is a formal decision point documented within the workflow.
Initial severity misclassification, causing the incident to be under-resourced or over-escalated from the start. Tier transitions losing critical diagnostic context, forcing the next responder to restart investigation. SLA timelines not monitored proactively, resulting in breaches that could have been prevented by earlier escalation. Escalation paths not updated to reflect current team structures or on-call rotations, routing incidents to unavailable responders. Post-incident reviews not conducted consistently, preventing the organization from improving escalation effectiveness over time.
Enforces tiered escalation paths with configurable severity classifications, SLA timelines, and response team routing at each level.
AI Agents monitor incident timelines proactively and trigger escalation before SLA thresholds are breached, reducing response delays.
Prepares comprehensive handoff summaries at each tier transition so incoming responders have immediate context without re-investigation.
Coordinates parallel response streams at higher escalation tiers, ensuring cross-functional teams work with shared visibility and clear ownership.
Connects to ITSM platforms like ServiceNow to synchronize incident data and ensure the escalation workflow reflects the current state of the incident across systems.