Go-live planning guide: A complete implementation transition framework



You've spent months on the implementation. The system is configured, the integrations are mapped, and the project plan shows green across the board. Then go-live day arrives, and everything falls apart.
The culprit isn't usually the technology. It's the transition.
Go-live is where implementations are won or lost. It's the moment when months of planning, configuration, and stakeholder alignment either click into place or collapse under the weight of poor coordination. The system works perfectly in testing, but nobody prepared the client's finance team for the new approval workflow.
The data migration was completed on schedule, but three critical integrations weren't tested with production volumes. The training was delivered, but half the users didn't attend because nobody confirmed the calendar invites.
These aren't edge cases. They're the norm. And they're entirely preventable.
If you're a senior implementation professional who refuses to let coordination failures derail your launches, this guide will give you the complete framework to make that happen.
Key takeaways
Go-live is a phase, not a date: Successful implementations treat go-live as a 30-day-before to 14-day-after transition, not a single launch moment. The teams that fail are the ones who plan for a day instead of a journey.
Three readiness pillars must align simultaneously: Operational readiness (systems validated), organizational readiness (users trained), and stakeholder readiness (executives aligned) all need to converge at launch. If even one lags, failure risk spikes.
Most breakdowns trace back to coordination, not technology: With 57% of project failures linked to communication gaps and 39% tied to unclear requirements, the transition often collapses because teams manage work across scattered tools and disconnected communication channels.
A structured, phased framework reduces execution risk: Following defined phases, readiness assessment, stakeholder alignment, dry run, cutover, and hypercare, creates predictable transitions and prevents the blind spots that surface during high-pressure cutover windows.
Real-time visibility outperforms static reporting: Centralized workflow orchestration gives stakeholders a shared understanding of status and ownership, reducing escalations, shortening issue resolution cycles, and keeping launches on track.
What defines effective go-live planning
Most implementation teams make the same fundamental mistake: they treat go-live as an event rather than a process. They circle a date on the calendar, work backward from that deadline, and assume the hard work ends when the system goes live. This is exactly backward.
The real challenge isn't building the technology, it's orchestrating the handoff. When your project tracker lives in one system, your communication in another, your documents in a third, and your client interactions scattered across email threads, coordination overhead compounds at precisely the moment you can least afford it.
Effective go-live planning brings three pillars into alignment at the same time. Operational readiness ensures your systems are validated, integrations tested, and data migration complete. Organizational readiness addresses the human side: users trained, change management executed, support structures in place. Stakeholder readiness guarantees alignment at the top: executives briefed, escalation paths defined, and communication cadences established.
This is precisely why workflow orchestration platforms like Moxo, have become essential for implementation teams. When every stakeholder, internal and external, can see exactly what needs to happen next, communication breakdowns become mathematically improbable.
SimplySolved, an accounting firm managing SME clients across the UAE, found that consolidating its implementation workflows into a single hub reduced operating expenses by 29% while maintaining 100% service delivery. As their Managing Director noted, "Everything is in one place, so it ensures the information isn't lost."
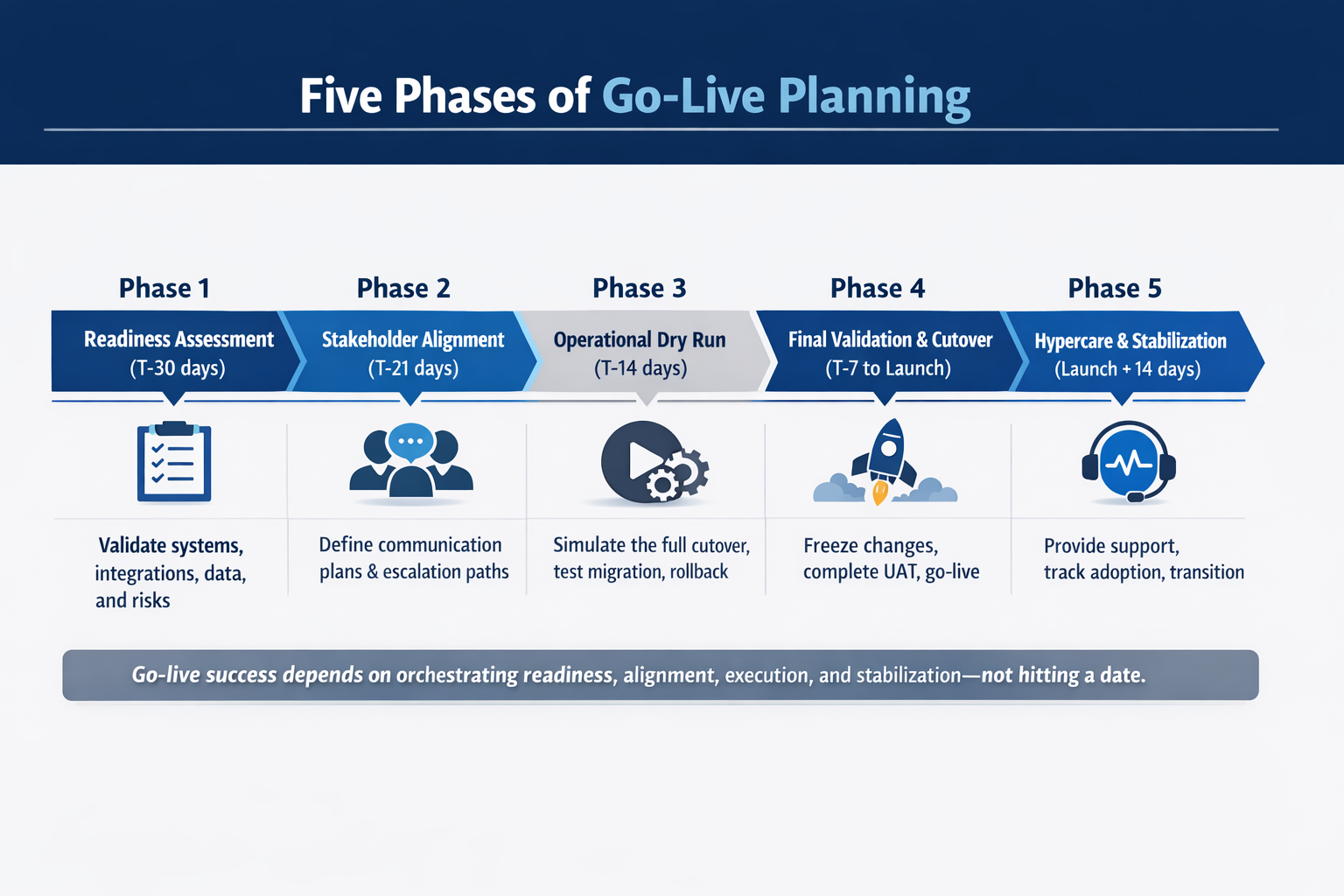
The five-phase go-live planning framework
The following framework transforms chaotic transitions into controlled, repeatable processes. Each phase addresses a specific failure mode that derails implementations, the kind that leaves project managers explaining to leadership why the system has been down for 72 hours.
Phase 1: Readiness assessment (T-30 days)
Most teams skip this step, which is why they're blindsided at launch. The assumption is dangerous but common: if individual workstreams are tracking green, the overall project must be ready. This ignores the reality that go-live failures rarely stem from a single broken component.
They emerge from the spaces between components. The integration was never tested with production data. The approval workflow works perfectly until it encounters an edge case. The reporting dashboard pulls from a table that hasn't been populated yet.
Begin with a comprehensive go/no-go evaluation that identifies every open item, dependency, and critical path blocker. The key deliverable is a readiness scorecard with risk-weighted items, not a checkbox exercise, but a prioritized view of what actually threatens your launch.
This is where you discover that the integration you assumed was complete actually hasn't been tested under realistic conditions. Understanding the complete customer workflow before launch prevents these surprises from becoming crises.
Phase 2: Stakeholder alignment (T-21 days)
Communication breakdowns don't happen because people refuse to communicate. They happen because everyone assumes someone else is handling it. The implementation team thinks the client's IT department is briefing end users. The client's IT department thinks the implementation team is handling training. End users show up on launch day having never seen the system.
This phase exists to eliminate assumptions.
Finalize your communication plans across all audience tiers: executives who need high-level status, end users who need to understand what changes for them, and support teams who need to know what's coming their way.
Confirm escalation protocols and decision-making authority before you need them, not during a crisis when nobody knows who can approve a rollback. Your deliverable is a RACI matrix that eliminates the "I thought you were handling that" conversations that derail launches.
With a centralized client portal, every stakeholder sees exactly what requires their action. No more chasing approvals through email chains that dead-end in someone's spam folder.
Phase 3: Operational dry run (T-14 days)
This is your insurance policy, and it's the phase most likely to get compressed when timelines slip. That compression is a mistake that compounds on launch day.
Execute a full system rehearsal in a production-equivalent environment. This means realistic data volumes, actual user accounts, and the complete end-to-end workflow, not a curated demo path that avoids the ugly corners.
Validate data integrity at every integration touchpoint. Confirm user access works the way it's supposed to, including the edge cases: What happens when someone's permissions haven't propagated? What happens when a required approver is out of office?
Most critically, test your rollback procedures. The teams that treat rollback as a sign of weakness are the ones who end up in extended outages because they never verified that the reversal process actually works.
Having a proper audit trail ensures every decision during this phase is documented. This becomes essential for post-launch analysis when you're trying to understand what went wrong and when.
Phase 4: Final validation and cutover (T-7 to launch)
The week before launch is not the time for heroics. It's time for discipline.
Complete user acceptance sign-off with actual sign-off, not verbal confirmation that gets forgotten, but documented approval that creates accountability. Freeze non-critical changes. The temptation to squeeze in one more enhancement is strong, but every change introduced in the final week is a change that hasn't been tested in the integrated environment.
Implement configuration lockdown and execute your cutover sequence per the documented runbook.
The signed go-live authorization from your project sponsor isn't bureaucracy. It's shared accountability that prevents finger-pointing later. When executives have formally approved the launch, they own the outcome alongside the implementation team.
Following proven customer onboarding best practices during cutover dramatically improves adoption rates because users encounter a system that behaves the way they were trained to expect.
Phase 5: Hypercare and stabilization (Launch + 14 days
Most failures don't surface at launch. The initial hours are typically calm because users are cautious, volumes are low, and everyone is watching carefully. The real test comes 48 to 72 hours later when edge cases emerge, users start taking shortcuts, and the excitement of go-live gives way to the grinding reality of production operations.
Deploy a dedicated support model with accelerated response SLAs during this window. The standard support queue that works fine for steady-state operations will buckle under the combination of volume and urgency that characterizes the hypercare period. Monitor system performance and user adoption daily, not weekly, not when someone complains, but proactively.
Falconi Consulting implemented structured workflows for their post-launch support and reduced project turnaround times by 40%, accelerating due diligence from weeks to days because they caught issues before those issues compounded.
Implementing customer support workflow best practices during hypercare ensures issues are resolved before they erode client confidence. The stabilization report and formal handoff to BAU support marks the true end of implementation, not the launch date. Until that handoff is complete, the project isn't done.
Go-live best practices from high-performing teams
Beyond the framework, four principles separate smooth go-lives from painful ones. These aren't theoretical best practices pulled from a textbook. They're patterns observed across hundreds of implementations, the common thread connecting projects that launch smoothly and those that spiral into chaos.
Communication over documentation
Real-time visibility beats static status reports every time. The instinct during high-pressure transitions is to document everything, to create comprehensive status decks and send detailed email updates. The problem is that nobody reads them. Or they read them three days late. Or they read them and misinterpret the implications because they lack context.
The biggest barrier to successful change projects isn't technical complexity. It's changing mindsets and attitudes. You can't change mindsets with a PDF attachment. Stakeholders need live dashboards that show exactly where things stand.
They need the ability to ask questions and get answers in context, not through a game of email telephone that takes 48 hours to resolve a simple clarification. Organizations using orchestrated workflows report dramatically faster resolutions because everyone sees the same reality at the same time.
Anticipate "Day Two" problems
Plan your support capacity for Day Two, not Day One. This seems counterintuitive. Launch day feels like the moment of maximum risk, the day when everything could go wrong. In practice, launch day is usually quiet. Users are tentative. Volumes are low. Everyone is paying attention.
The real chaos arrives 48 to 72 hours later. Edge cases emerge that nobody anticipated. Users discover workarounds that break downstream processes. The integration that tested perfectly starts throwing errors under production load. Support teams that were fully staffed for launch day have returned to normal schedules just as ticket volume spikes.
Professional services firms using structured implementation workflows consistently report faster ticket resolution and higher customer satisfaction scores. The difference isn't better technology. It's better planning. They staff for Day Two instead of Day One and build escalation paths before they need them.
Build reversibility into every decision
Rollback isn't failure. It's risk management. Every cutover step should have a documented reversal procedure, tested and verified before you need it.
The teams that treat rollback as a sign of weakness are the teams that end up in extended outages. They push forward when they should step back because stepping back feels like admitting defeat. They compound problems by layering fixes on top of fixes instead of returning to a known good state and trying again.
Peninsula Visa built this principle into their document processing workflows and dramatically reduced their processing time. When something went wrong, they could trace exactly where the failure occurred and reverse course without losing the audit trail. The ability to roll back quickly meant they could move forward confidently, knowing that mistakes were recoverable.
Centralize your command center
Scattered tools create scattered teams. When your project tracker lives in Jira, your communication happens in Slack, your documents sit in SharePoint, and your client interactions bounce between email and text messages, coordination overhead multiplies. Every handoff between systems is an opportunity for information to get lost. Every context switch costs time and attention.
When everyone operates from the same workspace, the "where is that document?" panic that derails launches simply doesn't happen. The status meeting that used to consume an hour becomes a five-minute check-in because the status is visible to everyone, all the time.
How Moxo helps
The framework above works regardless of what tools you use. But most go-live failures aren't caused by bad frameworks. They're caused by coordination friction that compounds at exactly the wrong moment. When your implementation team is chasing client approvals through email and your stakeholders are missing deadlines because reminders got buried, no framework will save you.
This is the problem Moxo was built to solve.
With Moxo, every stakeholder receives a magic link that drops them directly into the action item that needs their attention. No login credentials to remember. No hunting through folders.
Automated reminders ensure nothing falls through the cracks. The mobile app gives stakeholders full functionality from anywhere. Timelines and to-dos create visibility into exactly what's pending and who's responsible.
During hypercare, communication speed becomes critical. Moxo brings messaging, meeting scheduling, and video calls into the same workspace where the implementation is being managed. Recordings and transcripts become part of the permanent record.
Structured forms and approval workflows ensure every piece of documentation is captured and retrievable.
And AI agents handle repetitive coordination work, freeing your team to focus on judgment calls that require human expertise.
As one implementation lead noted in a G2 review: "Moxo has helped us completely streamline our project management and client communication process. Now, everything from client onboarding to task updates and file sharing happens in one central place. It's made our workflows much more organized, our team more accountable, and our clients more informed and confident in our process."
SimplySolved consolidated its implementation workflows into Moxo and reduced operating expenses while maintaining complete service delivery. The pattern is consistent: when coordination overhead disappears, implementation teams can focus on what actually matters.
Conclusion
Go-live success is earned in the planning phase, not the launch moment. The five-phase framework outlined here, readiness assessment, stakeholder alignment, operational dry run, final validation, and hypercare, provides a repeatable model that addresses the specific failure modes responsible for most implementation disasters.
The difference between controlled transition and chaotic launch comes down to orchestration: connecting the right people, processes, and systems at the right time. Teams that treat go-live as a phase rather than a date consistently outperform those who circle a calendar square and hope for the best.
Moxo's workflow orchestration platform was built for exactly this challenge. Implementation teams across financial services, consulting, and professional services use it to manage complex go-live transitions within a single client-facing workspace.
Structured workflows keep every stakeholder aligned on what needs to happen next. Real-time visibility eliminates the status update meetings that consume hours without advancing the project.
Complete audit trails satisfy enterprise compliance requirements while creating the documentation you need for post-launch analysis. The result is faster time-to-value and stronger client relationships that survive the stress of implementation.
Ready to transform your go-live process? See Moxo in action.
FAQs on go-live planning
What is go-live planning in implementation projects?
Go-live planning is the structured process of transitioning a system from implementation into live production. It involves coordinating people, processes, and technology across a phase that typically spans 30 days before launch through 14 days after, ensuring operational readiness and stakeholder alignment converge at the right moment.
What are the most common causes of go-live failures?
Communication breakdowns and weak requirements rarely exist in isolation. They are symptoms of a broader coordination failure. Teams can build solid technology and still watch it crumble during handoff because no one orchestrated the transition from implementation to production. When ownership, timing, and decision paths are unclear, even well-built systems struggle to survive the move to live operations.
What is hypercare in go-live planning?
Hypercare is the intensive post-launch support period, typically 14 days, with accelerated response SLAs and daily monitoring. Most failures surface 48–72 hours after launch when edge cases emerge, making this phase essential for catching issues before they compound into crises.
How can Moxo’s workflow orchestration improve go-live success rates?
Moxo’s workflow orchestration centralizes task management, automates notifications, and provides real-time visibility across all stakeholders. This eliminates the scattered tools and communication gaps responsible for most go-live failures.
